This type of sorting is called "Selection Sort" because it works by repeatedly element. It works as follows: first find the smallest in the array and exchange it with the element in the first position, then find the second smallest element and exchange it with the element in the second position, and continue in this way until the entire array is sorted. SELECTION SORT (A) for i ← 1 to n-1 do
Selection sort is among the simplest of sorting techniques and it work very well for small files. Furthermore, despite its evident "naïve approach "Selection sort has a quite important application because each item is actually moved at most once, Section sort is a method of choice for sorting files with very large objects (records) and small keys.
The worst case occurs if the array is already sorted in descending order. Nonetheless, the time require by selection sort algorithm is not very sensitive to the original order of the array to be sorted: the test "if A[j] < class="apple-converted-space"> j ← j; min x ← A[j] of this test are executed. The Selection sort spends most of its time trying to find the minimum element in the "unsorted" part of the array. It clearly shows the similarity between Selection sort and Bubble sort. Bubble sort "selects" the maximum remaining elements at each stage, but wastes some effort imparting some order to "unsorted" part of the array. Selection sort is quadratic in both the worst and the average case, and requires no extra memory. For each i from 1 to n - 1, there is one exchange and n - i comparisons, so there is a total of n -1 exchanges and (n -1) + (n -2) + . . . + 2 + 1 = n(n -1)/2 comparisons. These observations hold no matter what the input data is. In the worst case, this could be quadratic, but in the average case, this quantity is O(n log n). It implies that the running time of Selection sort is quite insensitive to the input. If the first few objects are already sorted, an unsorted object can be inserted in the sorted set in proper place. This is called insertion sort. An algorithm consider the elements one at a time, inserting each in its suitable place among those already considered (keeping them sorted). Insertion sort is an example of an incremental algorithm; it builds the sorted sequence one number at a time. This is perhaps the simplest example of the incremental insertion technique, where we build up a complicated structure on n items by first building it on n − 1 items and then making the necessary changes to fix things in adding the last item. The given sequences are typically stored in arrays. We also refer the numbers as keys. Along with each key may be additional information, known as satellite data. [Note that "satellite data" does not necessarily come from satellite!] Algorithm: Insertion Sort It works the way you might sort a hand of playing cards: We start with an empty left hand [sorted array] and the cards face down on the table [unsorted array]. Then remove one card [key] at a time from the table [unsorted array], and insert it into the correct position in the left hand [sorted array]. To find the correct position for the card, we compare it with each of the cards already in the hand, from right to left. Note that at all times, the cards held in the left hand are sorted, and these cards were originally the top cards of the pile on the table. Pseudocode We use a procedure INSERTION_SORT. It takes as parameters an array A[1.. n] and the length n of the array. The array A is sorted in place: the numbers are rearranged within the array, with at most a constant number outside the array at any time. INSERTION_SORT (A) 1. FOR j ← 2 TO length[A]
Example: Following figure (from CLRS) shows the operation of INSERTION-SORT on the array A= (5, 2, 4, 6, 1, 3). Each part shows what happens for a particular iteration with the value of j indicated. j indexes the "current card" being inserted into the hand. Read the figure row by row. Elements to the left of A[j] that are greater than A[j] move one position to the right, and A[j] moves into the evacuated position. Implementation void insertionSort(int numbers[], int array_size)
http://www.personal.kent.edu/~rmuhamma/Algorithms/MyAlgorithms/Sorting/insertionSort.htm Bubble sort is a simple and well-known sorting algorithm. It is used in practice once in a blue moon and its main application is to make an introduction to the sorting algorithms. Bubble sort belongs to O(n2) sorting algorithms, which makes it quite inefficient for sorting large data volumes. Bubble sort is stable and adaptive. You can imagine that on every step big bubbles float to the surface and stay there. At the step, when no bubble moves, sorting stops. Let us see an example of sorting an array to make the idea of bubble sort clearer. Example. Sort {5, 1, 12, -5, 16} using bubble sort. Average and worst case complexity of bubble sort is O(n2). Also, it makes O(n2) swaps in the worst case. Bubble sort is adaptive. It means that for almost sorted array it gives O(n) estimation. Avoid implementations, which don't check if the array is already sorted on every step (any swaps made). This check is necessary, in order to preserve adaptive property. One more problem of bubble sort is that its running time badly depends on the initial order of the elements. Big elements (rabbits) go up fast, while small ones (turtles) go down very slow. This problem is solved in the Cocktail sort. Turtle example. Thought, array {2, 3, 4, 5, 1} is almost sorted, it takes O(n2) iterations to sort an array. Element {1} is a turtle. Rabbit example. Array {6, 1, 2, 3, 4, 5} is almost sorted too, but it takes O(n) iterations to sort it. Element {6} is a rabbit. This example demonstrates adaptive property of the bubble sort. There are several ways to implement the bubble sort. Notice, that "swaps" check is absolutely necessary, in order to preserve adaptive property. void bubbleSort(int arr[], int n) { bool swapped = true; int j = 0; int tmp; while (swapped) { swapped = false; j++; for (int i = 0; i < n - j; i++) { if (arr[i] > arr[i + 1]) { tmp = arr[i]; arr[i] = arr[i + 1]; arr[i + 1] = tmp; swapped = true; } } } } Invented in 1959 by Donald Shell, the shell sort is a relatively fast algorithm and is easy to code. It attempts to roughly sort the data first, moving large elements towards one end and small elements towards the other. It performs several passes over the data, each finer than the last. After the final pass, the data is fully sorted. It is important to note that the shell sort algorithm does not actually sort the data itself; it increases the effeciency of other sorting algorithms. By roughly grouping the data, it reduces the number of times the data elements need to be rearranged in the sort process. Usually an insertion or bubble sort is used to arrange the data at each step, but other algorithms can be used. Shell sort does not noticably benefit the faster algorithms (such as merge and quicksort), and in some cases will actually reduce their performance. Sort routines that rely on directly swapping elements are most effectively combined with a shell sort. Shell sort quickly arranges data by sorting every nth element, where n can be any number less than half the number of data. Once the initial sort is performed, n is reduced, and the data is sorted again until n equals 1. It is vital that the data is finally sorted with n = 1, otherwise there may be out-of-order elements remaining. In this example, we will assume there is a selection sort being used to do the actual sorting. As mentioned above, we will be using an initial value of 3 for n. This is less than the maximum (which in this case is 4, because this is the largest number less than half the number of elements we have). We pretend that the only elements in the data set are elements containing 5, 8 and 9 (highlighted blue). Notice that this is every 3rd element (n is 3). After sorting these, we look at the elements to the right of the ones we just looked at. Repeat the sort and shift routine until all of the elements have been looked at once. So if n = 3, you will need to repeat this step 3 times to sort every element. Note that only the highlighted elements are ever changed; the ones with a white background are totally ignored. Now that all of the elements have been sorted once with n = 3, we repeat the process with the next value of n (2). If you look carefully, there is a general congregation of large numbers at the right hand side, and the smaller numbers are at the left. There are still quite a few misplaced numbers (most notably 8, 2, 5 and 6), but it is better sorted than it was. You can see now that the data is almost completely sorted - after just 2 more steps! All that remains is to sort it again with n = 1 to fix up any elements that are still out of order. Whenn = 1, we are just performing a normal sort, making sure every element in the dataset is in its correct place. You may wonder why don't we just skip to this step. Yes, doing that would work, however the selection and bubble sorts are fastest when the data is already sorted (or close to). The shell sort method orders the data in fewer steps than would be required for either of the above methods.SELECTION SORT
min j ← i;
min x ← A[i]
for j ← i + 1 to n do
If A[j] < class="apple-converted-space"> j ← j
min x ← A[j]
A[min j] ← A [i]
A[i] ← min x
Implementation
void selectionSort(int numbers[], int array_size){ int i, j; int min, temp; for (i = 0; i <> { min = i; for (j = i+1; j <> { if (numbers[j] <> min = j; } temp = numbers[i]; numbers[i] = numbers[min]; numbers[min] = temp; }}http://www.personal.kent.edu/~rmuhamma/Algorithms/MyAlgorithms/Sorting/selectionSort.htmINSERTION SORT
2. DO key ← A[j]
3. {Put A[j] into the sorted sequence A[1 . . j − 1]}
4. i ← j − 1
5. WHILE i > 0 and A[i] > key
6. DO A[i +1] ← A[i]
7. i ← i − 1
8. A[i + 1] ← key" src="http://www.personal.kent.edu/~rmuhamma/Algorithms/MyAlgorithms/Sorting/Gifs/insertion-fig2-2.gif">
{
int i, j, index;
for (i = 1; i < index =" numbers[i];">j = i;
while ((j > 0) && (numbers[j − 1] > index))
{
numbers[j] = numbers[j − 1];
j = j − 1;
}
numbers[j] = index;
}
}BUBBLE SORT
Algorithm
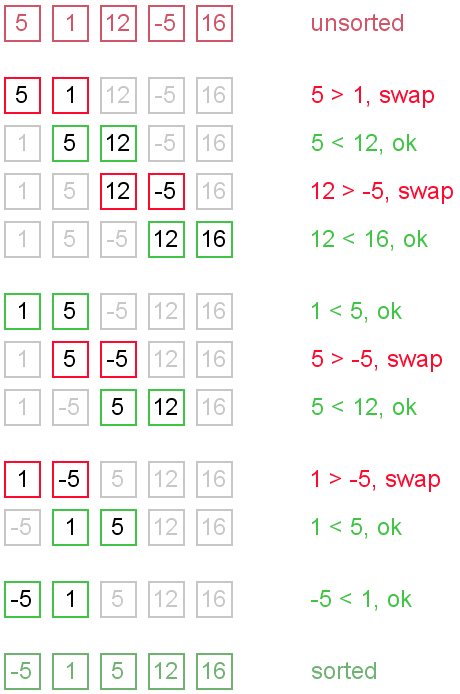
Complexity analysis
Turtles and rabbits


Code snippets
C++
SHELL SORTSelecting good values for n
Choosing n is not as difficult as it might seem. The only sequence you have to avoid is one constructed with the powers of 2. Do not choose (for example) 16 as your first n, and then keep dividing by 2 until you reach 1. It has been mathematically proven that using only numbers from the power series {1, 2, 4, 8, 16, 32, ...} produces the worst sorting times. The fastest times are (on average) obtained by choosing an initial n somewhere close to the maximum allowed and continually dividing by 2.2 until you reach 1 or less. Remember to always sort the data withn = 1 as the last step.
Example:
The data in the table needs to be sorted into ascending order. For simplicity, we have chosen the sequence {3, 2, 1} for our n. Elements in the table that have a white background are being ignored in that step. Elements with a blue background are the ones we are interested in. The top line of each table shows the data before we performed that step, the bottom shows the data afterwards.8 4 1 5 7 6 9 3 2 8 4 1 5 7 6 9 3 2 5 4 1 8 7 6 9 3 2 5 4 1 8 7 6 9 3 2 5 3 1 8 4 6 9 7 2 5 3 1 8 4 6 9 7 2 5 3 1 8 4 2 9 7 6 5 3 1 8 4 2 9 7 6 1 3 4 8 5 2 6 7 9 1 3 4 8 5 2 6 7 9 1 2 4 3 5 7 6 8 9 1 2 4 3 5 7 6 8 9 1 2 3 4 5 6 7 8 9
http://goanna.cs.rmit.edu.au/~stbird/Tutorials/ShellSort.html1 2 3 4 5 6 7 8 9
All about living my normal + simple life... Nothing personal, nothing interesting... :)
Subscribe to:
Post Comments (Atom)
About Me

- louie_pilongo
- Music gives me life... and my life is worth living... thanks god!
0 comments:
Post a Comment